Итоговый проект
Часть 3 · Машинное обучение
Регуляризованная регрессия (RidgeCV)
Лучшая α1000.0000
CV R² (mean)-0.007
CV R² (std)0.004
Test R²0.001
Test RMSE27516
Регуляризация L2 (Ridge) подавляет дисперсию коэффициентов и помогает, когда часть признаков коррелирует. Лучшее α подобрано кросс-валидацией: α=1000.0000. Если test R² близок к CV R², модель не переобучилась.
Кластеризация (KMeans, k = 4)
Inertia5996
Silhouette0.192
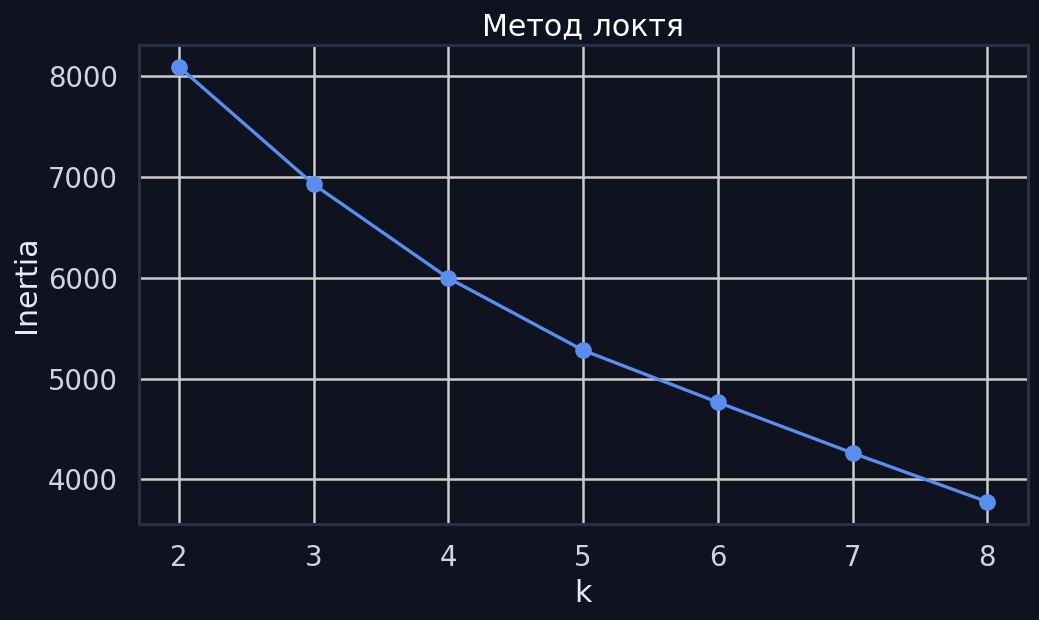
Метод локтя
Излом графика подсказывает оптимальное число кластеров.
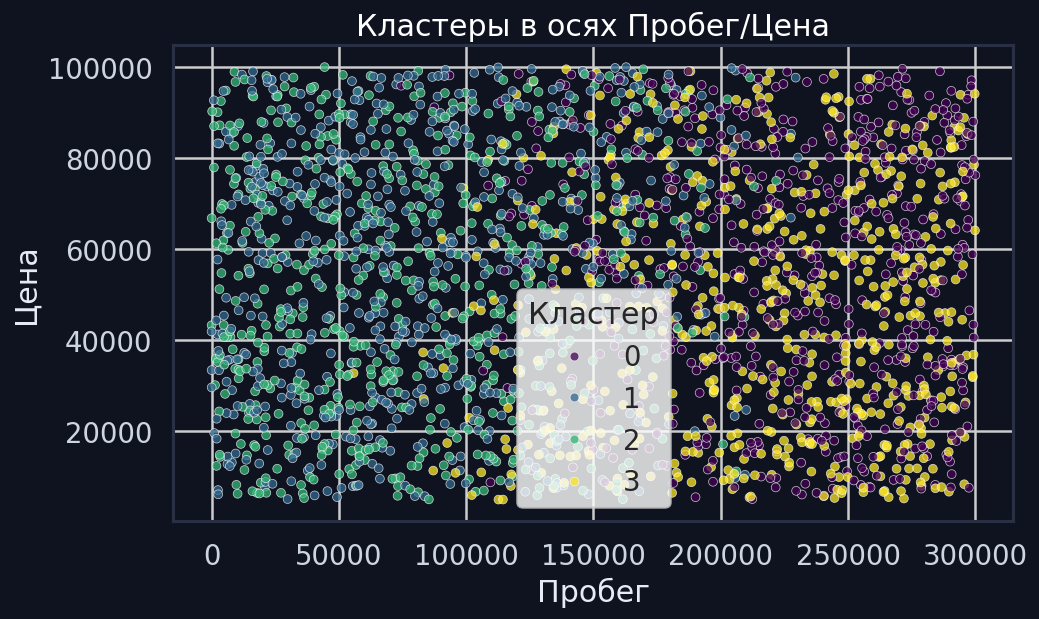
Кластеры
Цветом показана принадлежность кластеру в осях Пробег/Цена.
Профили кластеров
| Кластер | Размер | Год (среднее) | Объём двиг. | Пробег | Средняя цена |
|---|---|---|---|---|---|
| #0 | 619 | 2005.2 | 3.16 | 225667 | 55748 |
| #1 | 640 | 2010.6 | 4.89 | 83233 | 56121 |
| #2 | 633 | 2012.4 | 2.13 | 78036 | 51737 |
| #3 | 608 | 2018.4 | 3.67 | 217139 | 46744 |
Применение Generative AI для обогащения датасета
- Генерация синтетических наблюдений (например, через табличные модели CTGAN или TabDDPM) позволяет увеличить объём редких категорий — например, премиум-сегмент или электромобили.
- Балансировка классов в задаче кластеризации/классификации: GAN-модель даёт сэмплы, повторяющие совместное распределение признаков, что снижает смещение модели.
- LLM-агенты могут обогащать датасет внешними признаками (например, средняя цена топлива по году) и нормализовывать названия моделей и брендов.
- Diffusion-модели применяются для аугментации картинок автомобилей, если в датасет добавляются изображения. Это улучшает мультимодальные сценарии оценки стоимости.
- Главные риски: data leakage и снижение разнообразия — синтетика обязана проходить валидацию через статистические тесты (KS-test, корреляции) и hold-out проверку модели.